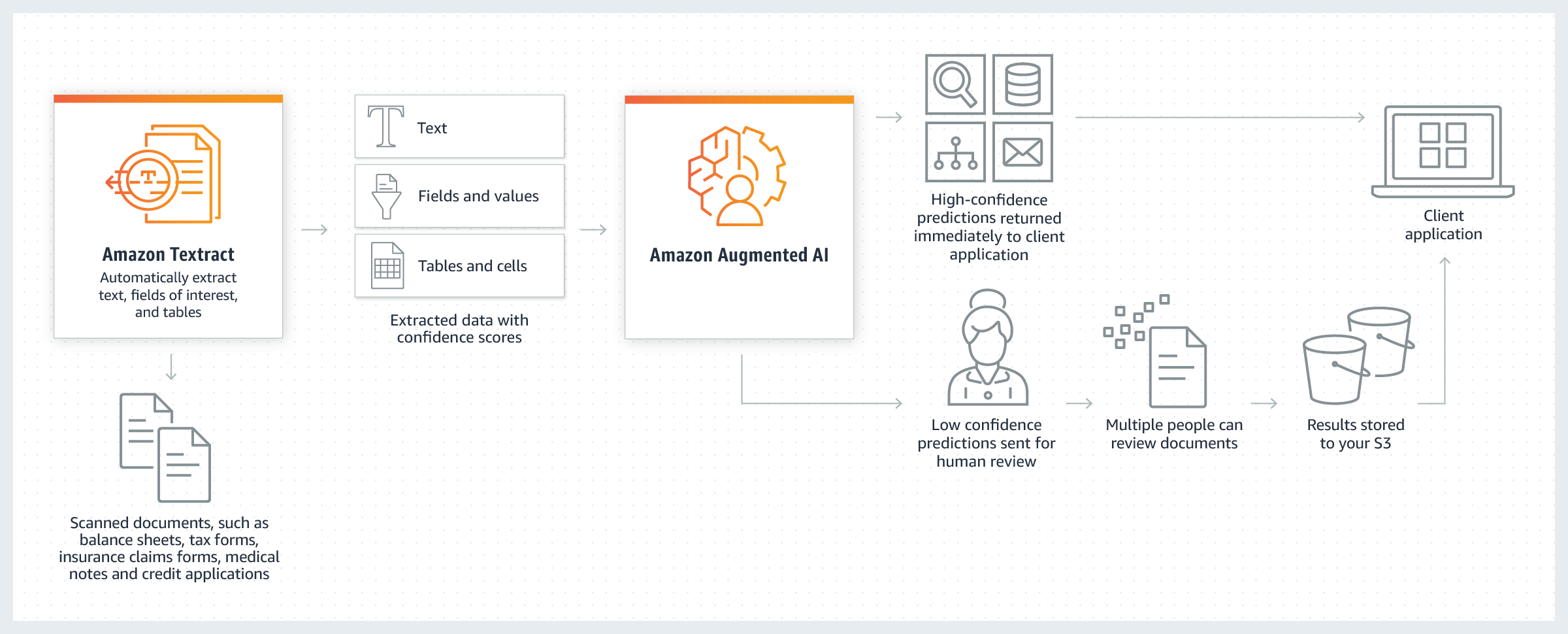
Easily extract text and data from your documents!
Amazon Textract is a service that automatically detects and extracts text and data from scanned documents. It goes beyond simple optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables.
Scan documents such as balance sheets, tax forms, insurance clams forms, medical notes and credit applications.
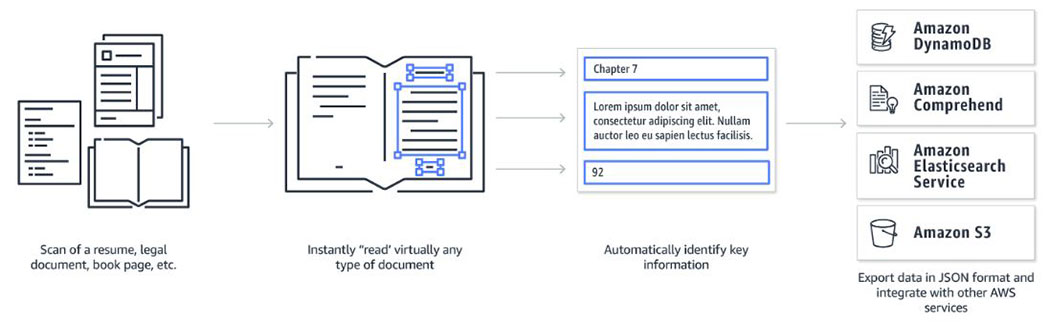
Optical Character Recognition (OCR)
Amazon Textract uses Optical Character Recognition (OCR) technology to automatically detect printed text, handwriting, and numbers in a scan or rendering of a document, such as a legal document or a scan of a book.
Form Extraction
Amazon Textract enables you to detect key-value pairs in document images automatically so that you can retain the inherent context of the document without any manual intervention. A key-value pair is a set of linked data items. For instance, on a document the field "First Name" would be the key and "Jane" would be the value. This makes it easy to import the extracted data into a database or to provide it as a variable into an application. With traditional OCR solutions, keys and values are extracted as simple text. The relationship between them is lost unless hard-coded rules are written and maintained for each form.
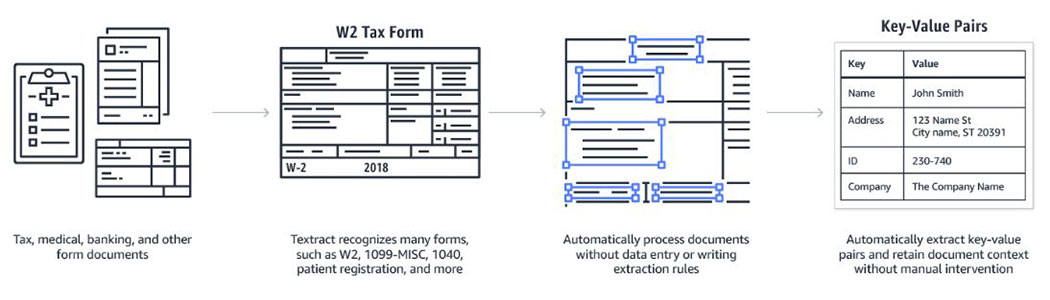
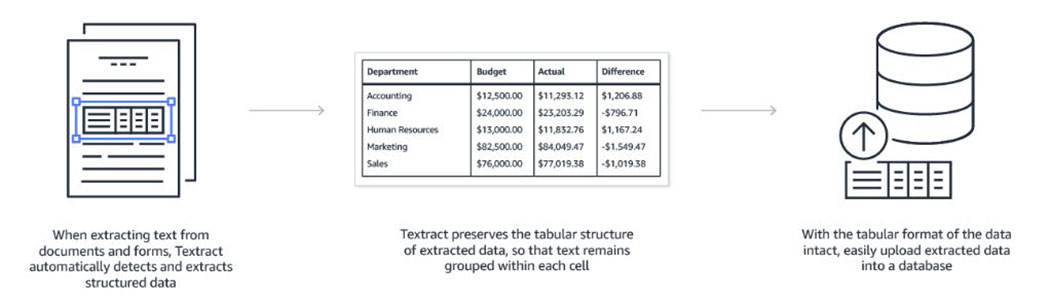
Table Extraction
Amazon Textract preserves the composition of data stored in tables during extraction. This is helpful for documents that are largely composed of structured data, such as financial reports or medical records that have column names in the top row of the table followed by rows of individual entries. You can use this feature to automatically load the extracted data into a database using a pre-defined schema. For example, rows of item numbers and quantities in an inventory report will retain their association to easily increment item totals in an inventory management application.
Amazon Textract
Amazon Textract preserves the composition of data stored in tables during extraction. This is helpful for documents that are largely composed of structured data, such as financial reports or medical records that have column names in the top row of the table followed by rows of individual entries. You can use this feature to automatically load the extracted data into a database using a pre-defined schema. For example, rows of item numbers and quantities in an inventory report will retain their association to easily increment item totals in an inventory management application.
Amazon Textract
Optical Character Recognition
$29.99 /
month
- Optical Character Recognition
- Detect key-value pairs in document
- Handwriting Recognition
Optical Character Recognition
$29.99 /
USD/user/month (billed monthly)